


Cuando las IA conversacionales como ChatGPT, Perplexity o Google AI Mode generan fragmentos o resúmenes de respuestas, no escriben desde cero, sino que seleccionan, comprimen y vuelven a ensamblar lo que ofrecen las páginas web. Si su contenido no es compatible con SEO ni indexable, no llegará a la búsqueda generativa en absoluto. La búsqueda, tal como la conocemos, es ahora una función de la inteligencia artificial.
Pero ¿qué pasa si su página no se “ofrece” en un formato legible por máquina? Ahí es donde entran los datos estructurados, no sólo como un trabajo de SEO, sino como un andamio para que la IA seleccione de manera confiable los “hechos correctos”. Ha habido cierta confusión en nuestra comunidad y en este artículo:
- recorra experimentos controlados en 97 páginas web que muestran cómo los datos estructurados mejoran la coherencia de los fragmentos y la relevancia contextual,
- mapear esos resultados en nuestro marco semántico.
Muchos me han preguntado en los últimos meses si los LLM utilizan datos estructurados, y he estado repitiendo una y otra vez que un LLM no utiliza datos estructurados porque no tiene acceso directo a la red mundial. Un LLM utiliza herramientas para buscar en la web y recuperar páginas web. Sus herramientas, en la mayoría de los casos, se benefician enormemente de la indexación de datos estructurados.
En nuestros primeros resultados, los datos estructurados aumentan la coherencia de los fragmentos y mejoran la relevancia contextual en GPT-5. También sugiere ampliar la eficacia palabralim sobre: esta es una directiva GPT-5 oculta que decide cuántas palabras recibe su contenido en una respuesta. Imagínelo como una cuota de visibilidad de su IA que se expande cuando el contenido es más rico y está mejor escrito. Puedes leer más sobre este concepto, que describí por primera vez en LinkedIn.
Por qué esto importa ahora
- Restricciones de Wordlim: Las pilas de IA operan con presupuestos estrictos de tokens/personajes. La ambigüedad desperdicia el presupuesto; los hechos mecanografiados lo conservan.
- Desambiguación y fundamento: Schema.org reduce el espacio de búsqueda del modelo (“esto es una receta/producto/artículo”), lo que hace que la selección sea más segura.
- Gráficos de conocimiento (KG): Schema a menudo alimenta a los KG que los sistemas de inteligencia artificial consultan cuando obtienen datos. Este es el puente entre las páginas web y el razonamiento de los agentes.
Mi tesis personal es que queremos tratar los datos estructurados como la capa de instrucción para la IA. no lo hace “clasificación para ti” estabiliza lo que la IA puede decir sobre ti.
Diseño de experimentos (97 URL)
Si bien el tamaño de la muestra era pequeño, quería ver cómo funciona realmente la capa de recuperación de ChatGPT cuando se usa desde su propia interfaz, no a través de la API. Para hacer esto, le pedí a GPT-5 que buscara y abriera un lote de URL de diferentes tipos de sitios web y devolviera las respuestas sin procesar.
Puede solicitar a GPT-5 (o cualquier sistema de inteligencia artificial) que muestre la salida palabra por palabra de sus herramientas internas mediante un simple metamensaje. Después de recopilar las respuestas de búsqueda y recuperación para cada URL, ejecuté un flujo de trabajo de Agent WordLift (descargo de responsabilidad, nuestro Agente AI SEO) para analizar cada página, verificar si incluía datos estructurados y, de ser así, identificar los tipos de esquemas específicos detectados.
Estos dos pasos produjeron un conjunto de datos de 97 URL, anotadas con campos clave:
- has_sd → Indicador Verdadero/Falso para presencia de datos estructurados.
- clases_esquema → el tipo detectado (por ejemplo, Receta, Producto, Artículo).
- buscar_raw → el fragmento de “estilo de búsqueda”, que representa lo que mostró la herramienta de búsqueda de IA.
- abierto_raw → un resumen del buscador o un vistazo estructural de la página mediante GPT-5.
Utilizando un enfoque de “LLM-as-a-Judge” impulsado por Gemini 2.5 Pro, analicé el conjunto de datos para extraer tres métricas principales:
- Consistencia: Distribución de longitudes de fragmentos de search_raw (diagrama de caja).
- Relevancia contextual: Cobertura de campos y palabras clave en open_raw por tipo de página (receta, comunicación electrónica, artículo).
- Puntuación de calidad: un índice conservador de 0 a 1 que combina presencia de palabras clave, señales NER básicas (para comercio electrónico) y ecos de esquema en el resultado de la búsqueda.
La cuota oculta: desempaquetando”palabralim“
Mientras realizaba estas pruebas, noté otro patrón sutil, uno que podría explicar por qué los datos estructurados generan fragmentos más consistentes y completos. Dentro del proceso de recuperación de GPT-5, hay una directiva interna conocida informalmente como wordlim: una cuota dinámica que determina cuánto texto de una sola página web puede convertirse en una respuesta generada.
A primera vista, actúa como un límite de palabras, pero es adaptable. Cuanto más rico y mejor escrito sea el contenido de una página, más espacio ganará en la ventana de síntesis del modelo.
De mis observaciones en curso:
- Contenido no estructurado (por ejemplo, una publicación de blog estándar) tiende a tener alrededor de ~200 palabras.
- Contenido estructurado (p. ej., marcado de productos, feeds) se extiende a ~500 palabras.
- Fuentes densas y autorizadas (API, trabajos de investigación) pueden alcanzar más de 1000 palabras.
Esto no es arbitrario. El límite ayuda a los sistemas de IA:
- Fomente la síntesis entre fuentes en lugar de copiar y pegar.
- Evite problemas de derechos de autor.
- Mantenga las respuestas concisas y legibles.
Sin embargo, también introduce una nueva frontera de SEO: sus datos estructurados aumentan efectivamente su cuota de visibilidad. Si sus datos no están estructurados, su límite es el mínimo; si es así, le otorga a la IA más confianza y más espacio para presentar su marca.
Si bien el conjunto de datos aún no es lo suficientemente grande como para ser estadísticamente significativo en todos los sectores verticales, los primeros patrones ya son claros y procesables.
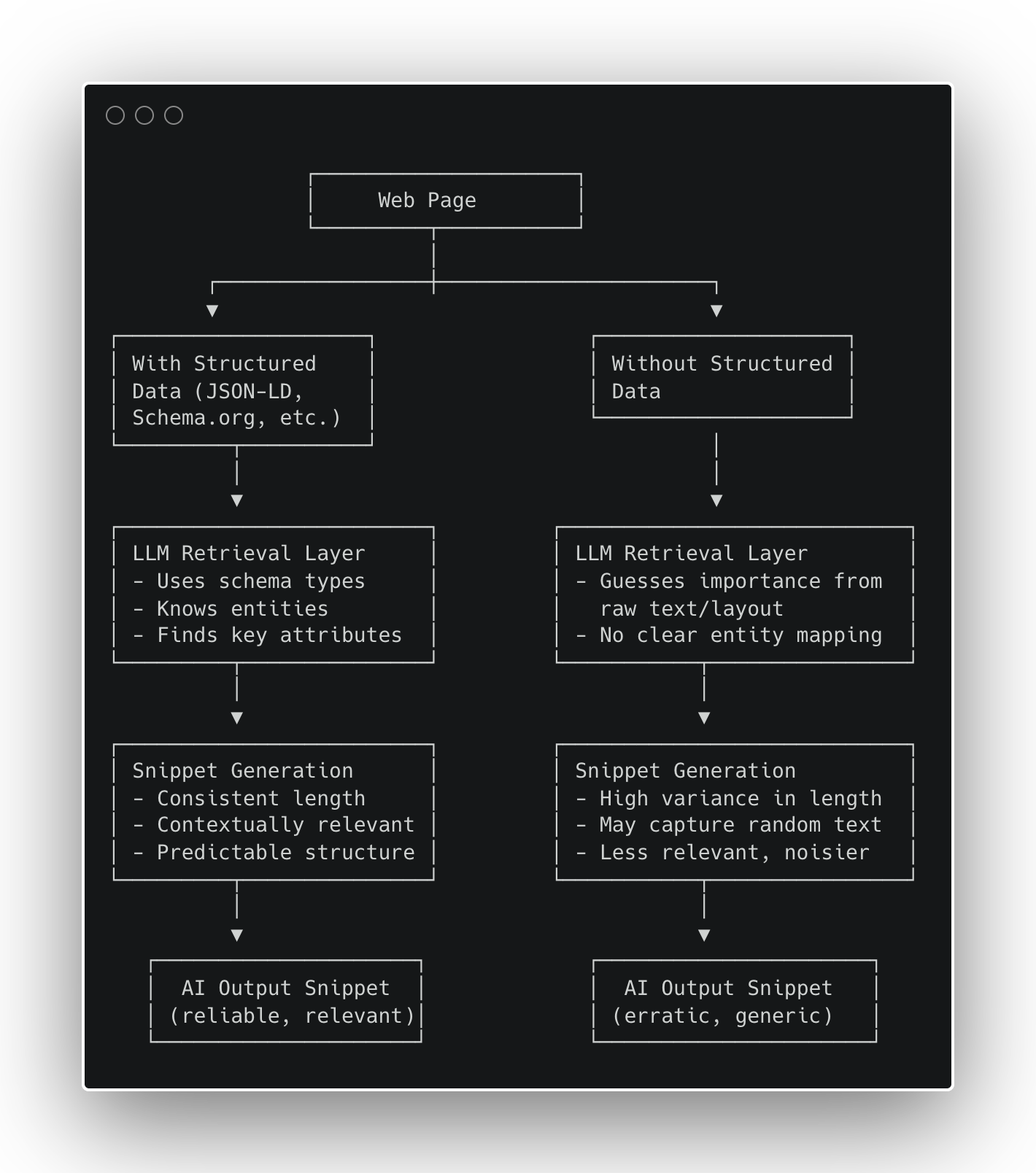 Figura 1: Cómo los datos estructurados afectan la generación de fragmentos de IA (Imagen del autor, octubre de 2025)
Figura 1: Cómo los datos estructurados afectan la generación de fragmentos de IA (Imagen del autor, octubre de 2025)Resultados
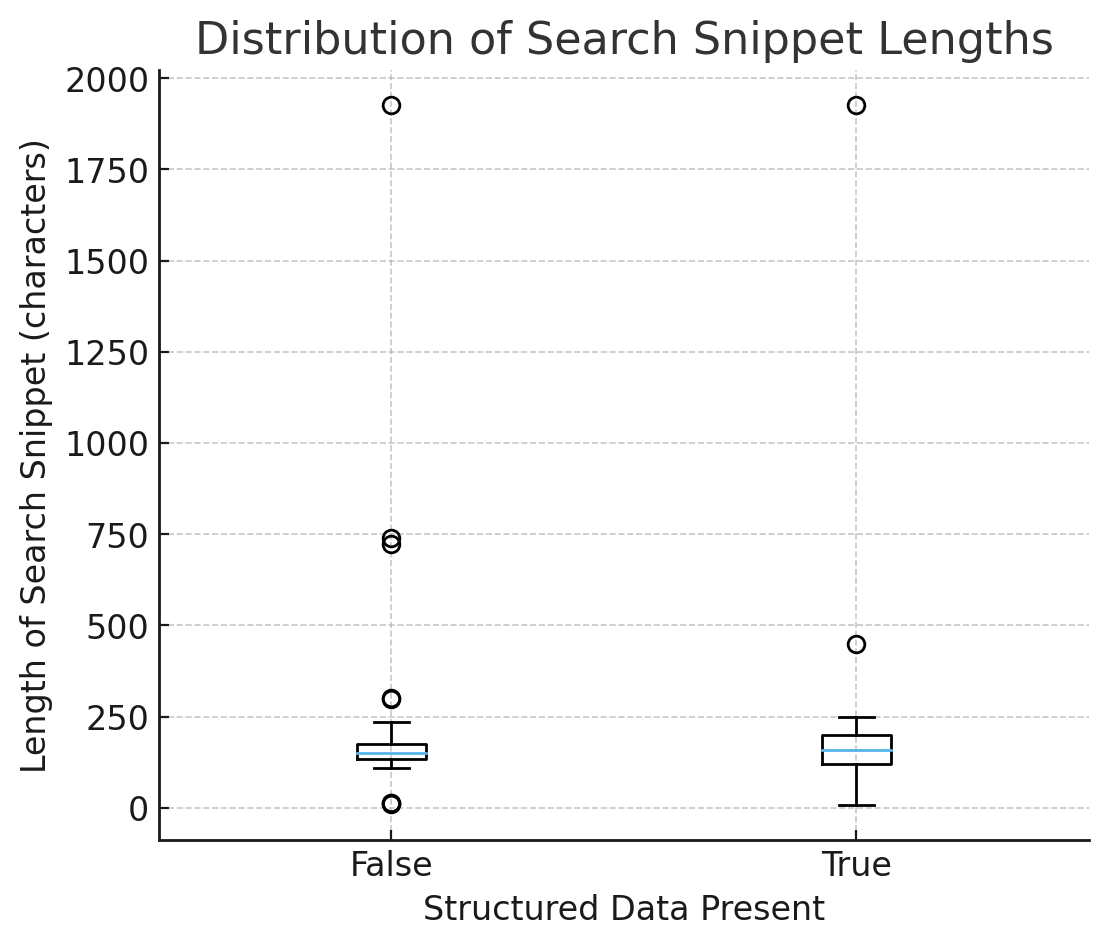 Figura 2: Distribución de la longitud de los fragmentos de búsqueda (Imagen del autor, octubre de 2025)
Figura 2: Distribución de la longitud de los fragmentos de búsqueda (Imagen del autor, octubre de 2025)1) Coherencia: los fragmentos son más predecibles con el esquema
En el diagrama de caja de la longitud de los fragmentos de búsqueda (con y sin datos estructurados):
- Las medianas son similares → el esquema no hace que los fragmentos sean más largos o más cortos en promedio.
- La extensión (IQR y bigotes) es más ajustada cuando has_sd = Verdadero → resultados menos erráticos, resúmenes más predecibles.
Interpretación: Los datos estructurados no inflan la longitud; reduce la incertidumbre. Los modelos utilizan de forma predeterminada datos escritos y seguros en lugar de adivinar a partir de HTML arbitrario.
2) Relevancia contextual: extracción de guías de esquema
- Recetas: Con Receta esquema, es mucho más probable que los resúmenes de búsqueda incluyan ingredientes y pasos. Elevación clara y mensurable.
- Comercio electrónico: La herramienta de búsqueda a menudo hace eco de los campos JSON-LD (p. ej., calificación agregada, oferta, marca) evidencia de que el esquema se lee y sale a la luz. Los resúmenes de búsqueda se inclinan hacia nombres exactos de productos en lugar de términos genéricos como “precio”, pero el anclaje de la identidad es más fuerte con el esquema.
- Artículos: Ganancias pequeñas pero presentes (es más probable que aparezca autor/fecha/título).
3) Nivel de calidad (todas las páginas)
Promediando la puntuación de 0 a 1 en todas las páginas:
- Sin esquema → ~0.00
- Con esquema → aumento positivo, impulsado principalmente por recetas y algunos artículos.
Incluso cuando las medias parecen similares, la varianza colapsa con el esquema. En un mundo de IA limitado por palabralim y gastos generales de recuperación, la baja variación es una ventaja competitiva.
Más allá de la coherencia: datos más completos amplían el alcance de Wordlim (señal temprana)
Si bien el conjunto de datos aún no es lo suficientemente grande como para realizar pruebas de significancia, observamos este patrón emergente:
Las páginas con datos estructurados de múltiples entidades más ricos tienden a generar fragmentos ligeramente más largos y densos antes del truncamiento.
Hipótesis: hechos tipificados e interconectados (p. ej., Producto + Oferta + Marca + Calificación agregada, o Artículo + autor + fecha de publicación) ayudan a los modelos a priorizar y comprimir información de mayor valor, ampliando de manera efectiva el presupuesto de tokens utilizables para esa página.
Las páginas sin esquema suelen truncarse prematuramente, probablemente debido a la incertidumbre sobre la relevancia.
Siguiente paso: mediremos la relación entre la riqueza semántica (recuento de distintas entidades/atributos de Schema.org) y la longitud efectiva del fragmento. Si se confirma, los datos estructurados no solo estabilizan los fragmentos, sino que aumentan el rendimiento informativo bajo límites constantes de palabras.
Del esquema a la estrategia: el libro de jugadas
Estructuramos sitios como:
- Gráfico de entidad (Esquema/GS1/Artículos/…): productos, ofertas, categorías, compatibilidad, ubicaciones, políticas;
- Gráfico léxico: Copia fragmentada (instrucciones de cuidado, guías de tallas, preguntas frecuentes) vinculada a entidades.
Por qué funciona: La capa de entidad proporciona a la IA un andamiaje seguro; la capa léxica proporciona evidencia reutilizable y citable. Juntos impulsan la precisión bajo lapalabralim restricciones.
Así es como traducimos estos hallazgos en un manual de estrategias de SEO repetible para marcas que trabajan bajo limitaciones de descubrimiento de IA.
- Enviar JSON‑LD para plantillas principales
- Recetas → Receta (ingredientes, instrucciones, rendimientos, tiempos).
- Productos → Producto + Oferta (marca, GTIN/SKU, precio, disponibilidad, calificaciones).
- Artículos → Artículo/NoticiaArtículo (título, autor, fechaPublicado).
- Unificar entidad + léxico
Mantenga las especificaciones, las preguntas frecuentes y el texto de las políticas fragmentados y vinculados a entidades. - Endurecer la superficie del fragmento
Los hechos deben ser coherentes en HTML visible y JSON‑LD; Mantenga los datos críticos en la mitad superior de la página y estables. - Instrumento
Realice un seguimiento de la variación, no solo de los promedios. Compare la cobertura de campos/palabras clave dentro de los resúmenes de máquinas por plantilla.
Conclusión
Los datos estructurados no cambian el tamaño promedio de los fragmentos de IA; cambia su certeza. Estabiliza los resúmenes y da forma a lo que incluyen. En GPT-5, especialmente bajo agresivo. palabralim En estas condiciones, esa confiabilidad se traduce en respuestas de mayor calidad, menos alucinaciones y una mayor visibilidad de la marca en los resultados generados por la IA.
Para los SEO y los equipos de producto, la conclusión es clara: trate los datos estructurados como infraestructura central. Si sus plantillas aún carecen de una semántica HTML sólida, no saltes directamente a JSON-LD: primero arregle los cimientos. Comience limpiando su marcado y luego coloque capas de datos estructurados encima para generar precisión semántica y capacidad de descubrimiento a largo plazo. En la búsqueda por IA, la semántica es la nueva superficie.
Más recursos:
Imagen de portada: TierneyMJ/Shutterstock

